A while ago, I saw a classification competition on Kaggle in which calibration through isotonic regression was an important element in the winning entry. I’ve long since forgot what the competition was, but it got me looking into some calibrators. Ever since, I’ve been meaning to try things out on some hockey data.
The most natural classification task in hockey is expected goals, so that’s what we’ll be playing with. The three calibration techniques we’ll compare are Platt scaling, isotonic regression, and Venn-ABERS.
xG
It’s been probably a couple years since I last updated my NHL xG model. Since this project wasn’t about getting the most out of the xG model, I opted for simplicity rather than throwing in all the bells and whistles.
For training the model, I used 5-on-5 shots between the goal line and the offensive blue line from last season (2022/23).
I opted for an out-of-the-box CatBoost model. From my experience, of the three main boosting libraries, CatBoost shows the best performance when not bothering with tuning hyperparameters.
The only features included in the model were the x and y-coordinates, the shot type, and, for rebounds, how much time had passed since the previous shot. The coordinates included monotonic constraints to ensure shots closer to the net would always have higher xG values than those farther away.
And just because I like these kinds of plots, here’s how the model is predicting non-rebounds for some different shot types.

Calibration
While the model provides results in the range of 0 to 1 that can be interpreted as probabilities, there’s no guarantee these will accurately reflect the true likelihood of a puck going in. In fact, this model consistently over-predicts the chances of a goal on the training set.

This results in an extra 461 predicted goals.
To tame these overzealous predictions, we’ll look at three different calibrators.
Platt scaling works by fitting a logistic regression to the results of the model. That is, instead of using the feature set to fit a logistic regression, it uses the predictions as the feature set for the logistic regression.
Isotonic regression fits a non-decreasing, step-wise function to minimize the squared differences between the predictions and the actual results.

Venn-ABERS performs isotonic regression twice, once for each class. In our case, that’s non-goals (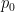
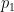

Platt scaling and isotonic regression are both provided by scikit-learn. For Venn-ABERS, I used Ivan Petej’s package.
Metrics
We’ll apply the calibrators to the 2022/23 data and test them out on data from this season as of whenever I scraped it (up to and including Wednesday). To compare the models, we’ll look at:
- How many total expected goals they predict (there were 4992 actual goals)
- Area under the ROC curve (AUC)
- Brier score (fancy mean squared error)
- Log loss
- Matthews correlation coefficient (MCC)
| Uncalibrated | Platt Scaling | Isotonic Regression | Venn-ABERS | |
| Total xG | 5184 (+192) | 4981 (-11) | 4807 (-185) | 4838 (-154) |
| AUC | 0.763 | 0.763 | 0.762 | 0.763 |
| Brier score | 0.055 | 0.056 | 0.055 | 0.055 |
| Log loss | 0.206 | 0.212 | 0.215 | 0.206 |
| MCC | 0.208 | 0.208 | 0.207 | 0.207 |
The uncalibrated model is outperforming the calibrators slightly on every metric, but is doing the worst in terms of total expected goals. It’s also the only one overpredicting goals.
While most models predict numbers strictly greater than 0 and less than 1, isotonic regression will actually cause some shots to be predicted as exactly 0 or 1. Scikit-learn’s implementation of log loss clips the oversized results caused by that, but it’s probably why some extra logs are lost by that model.
ECE
There’s one more metric I want to look at. When doing a bit of reading on the subject, I came across a paper by Dirar Sweidan and Ulf Johansson. In it, they looked at expected calibration error (ECE) when comparing these same calibrators. ECE is basically a weighted average of how the model’s outputs perform within different bins. This pairs nicely with some calibration plots.

Every version of the model is overpredicting expected goals on what it considers high danger chances and, in every case, the calibrators appear to exacerbate the issue. However, this is using uniform bin sizes. As the size of the squares suggests, there are a lot more low xG shots than high. In fact, there are more shots in the lowest bin than the rest of the bins combined. So let’s even that out a bit.

Platt scaling had the closest total number of goals, but appears to have the poorest calibration. It gets to a reasonable total by overpredicting the low end and underpredicting the mid-range. The uncalibrated model, isotonic regression, and Venn-ABERS all have pretty similar results. Let’s drop every prediction above 0.1 to see how well-calibrated they are on the low end.

The uncalibrated model is overpredicting expected goals slightly at the low end while isotonic regression and Venn-ABERS are both slightly underpredicting them.
When I made my model for predicting xG on blocked shots, I found the model was slightly better at predicting out-of-sample scoring, even when the blocked shots weren’t included in the calculations. Because that model does more to tamp down xG on shots from distance than it does shots from in close, my suspicion has been that giving even less weight to low quality opportunities is what’s beneficial in that regard.
That’s why I wanted to look at these low xG shots. There’s no guarantee that the calibrators will work in this way for any given xG model, but if they do help drop xG on the low danger chances, that could be an advantage in using them. I don’t know if it’s a big enough advantage to justify adding an extra step and dependency, but a potential advantage nevertheless.
Team Results
Finally, if you build an xG model, you might as well look at how teams are faring. This is using the Venn-ABERS calibrated results. It shows xGF in blue, xGA in red, and the yellow dots are how the actual goal differential compares. Teams with their logo on the left are underperforming their xG and teams on the right are overperforming.

